


Niedawno grupa naukowców Microsoft ogłosiła informację o opracowaniu systemu tłumaczenia maszynowego z języka chińskiego na język angielski, który tłumaczy wiadomości nie gorzej niż człowiek. Specjaliści Microsoftu wykorzystywali Sztuczną Inteligencję (SI) w celu poprawy jakości przetwarzanych tekstów. SI pozwoliło osiągnąć tłumaczeniu maszynowemu poziom tak zwanego „ludzkiego parytetu” – brak statystycznej różnicy między tłumaczeniem komputera a profesjonalnego tłumacza. EKD opowiada o rozwoju tej technologii i o tym, dlaczego pojawienie się zaawansowanego systemu tłumaczenia maszynowego nie jest końcem zawodu tłumacza.
Pierwsze kroki
Po raz pierwszy w historii termin „tłumaczenie maszynowe” wprowadził Warren Weaver w odległym 1949 roku w memorandum o przekładzie. Po dwóch latach naukowcy Instytutu Technicznego Massachusetts (MIT) rozpoczęli badania w tym zakresie pod kierownictwem Jahoszuy Bar-Hillela, pioniera w dziedzinie tłumaczenia maszynowego i językoznawstwa. Rosyjscy naukowcy zainteresowali się tematem tłumaczenia maszynowego w 1955 roku, równocześnie z kolegami z Japonii i Wielkiej Brytanii. W 1957 roku Chiny stały się czwartym krajem w świecie, zajmującym się rozwojem tłumaczenia maszynowego z języka chińskiego na rosyjski, przez co w Instytucie Języków została stworzona specjalna grupa badawcza. Wzrost zainteresowania nową technologią skłonił do otwarcia w USA pierwszych ośrodków badawczych w celu rozwinięcia tłumaczenia maszynowego: Association for Computational Linguistics (1962) i Automatic Language Processing Advisory Committee (ALPAC) (1964).
Do roku 1966 członkowie ALPAC próbowali uzyskać od maszyny tłumaczenie ekwiwalentne ludzkiemu. Szybko doszli oni do wniosku, że na tym poziomie technologicznym nie było to możliwe. Jednakże do 1995 roku zebrali obszerną bazę tłumaczeń maszynowych abstrakcyjnych wyrażeń z języka francuskiego, angielskiego, niemieckiego i hiszpańskiego. Firma Trados w 1989 roku wypuściła na światowy rynek technologię zapamiętywania przekładów, która pozwalała człowiekowi nie tłumaczyć tego samego zdania po raz kolejny. W 1991 roku badacze Uniwersytetu Charkowskiego stworzyli program tłumaczenia maszynowego z par językowych rosyjsko-angielskich i niemiecko-ukraińskich. W Chinach tłumaczenie maszynowe do 1991 roku nie osiągnęło znaczących sukcesów, jednak pojawienie się pierwszych prywatnych systemów tłumaczeń maszynowych odmieniło sytuację. Pierwszym takim programem był Transtar, po którym pojawiły się państwowe systemy IMC/EC, wchodząc na nowy poziom przekładu, w porównaniu z ich poprzednikami.
Wraz z rozprzestrzenieniem się internetu nastąpiła złota era technologii tłumaczenia maszynowego. Na przełomie wieków pojawiły się serwisy, pozwalające tłumaczyć niewielkie fragmenty tekstów online: Systran (1996), AltaVista Babelfish (1997), Google Translate (2006) i MOSES (2007). W zeszłym roku wzięły świat szturmem sieci neuronowe i uczenie maszynowe, i rozpoczął się nowy etap rozwoju tłumaczenia maszynowego.
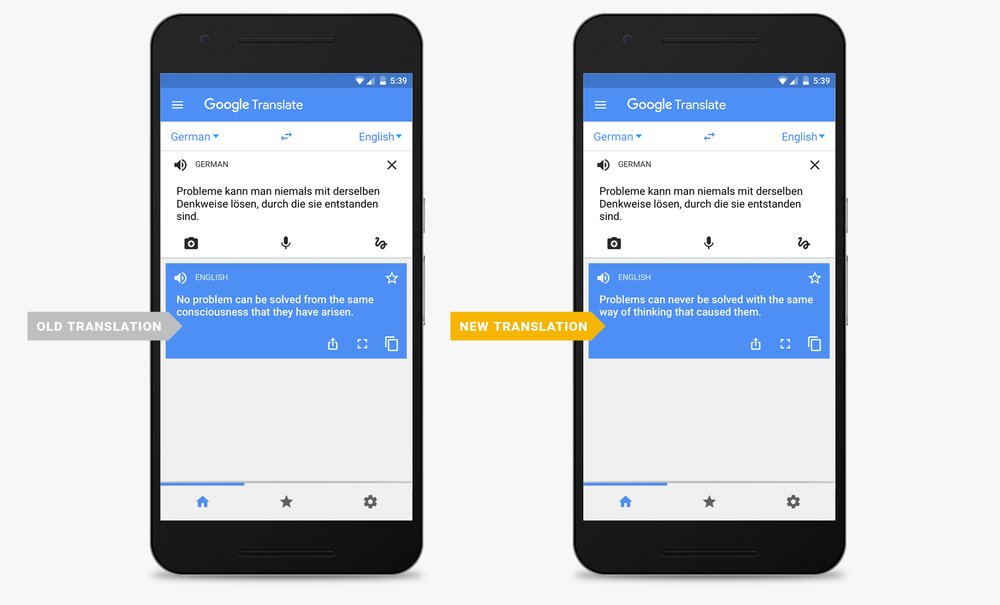 Microsoft jako jedna z pierwszych firm uruchomił stronę demonstracyjną pokazującą możliwości tłumaczenia maszynowego na podstawie sieci neuronowych i opublikował szczegółowy dokument z opisem metod zaprogramowania systemu. W marcu 2017 roku Google wdrożyło sieć neuronową Neural Machine Translation (NMT) i rozpoczęło publiczne testy w języku rosyjskim. W maju Facebook stworzył instrument faiseq na podstawie sieci konwolucyjnych, które przeważnie służą do efektywnego rozpoznawania obrazów, dzięki którym szybkość przekładu wzrosła dziewięciokrotnie.
Microsoft jako jedna z pierwszych firm uruchomił stronę demonstracyjną pokazującą możliwości tłumaczenia maszynowego na podstawie sieci neuronowych i opublikował szczegółowy dokument z opisem metod zaprogramowania systemu. W marcu 2017 roku Google wdrożyło sieć neuronową Neural Machine Translation (NMT) i rozpoczęło publiczne testy w języku rosyjskim. W maju Facebook stworzył instrument faiseq na podstawie sieci konwolucyjnych, które przeważnie służą do efektywnego rozpoznawania obrazów, dzięki którym szybkość przekładu wzrosła dziewięciokrotnie.
Jednak mnogość dostępnych serwisów, wdrożenie technologii uczenia maszynowego i sieci neuronowych nie rozwiązało głównego problemu przeciętnych użytkowników – niskiej jakości przekładów. Sens tłumaczonych tekstów jest gubiony w stercie błędów stylistycznych, leksykalnych a nawet gramatycznych.
Kamień milowy
 Usprawnienie algorytmów i wdrożenie sieci neuronowych do tłumaczenia maszynowego nie zmniejszył liczby problemów znaczeniowych przy wykorzystaniu serwisów takich jak Google Translate. Do tej pory istnieje ryzyko napotkania na kuriozalne błędy przy tłumaczeniu nawet najprostszych zdań typu „This coference is gonna make me miss my train”, gdzie zamiast logicznego „Przez tę konferencję przegapię pociąg” uzyskamy „Ta konferencja zmusi mnie do tęsknoty za moim pociągiem”. Angielski czasownik miss posiada wiele znaczeń, a komputer „nie zrozumiał” kontekstu.
Usprawnienie algorytmów i wdrożenie sieci neuronowych do tłumaczenia maszynowego nie zmniejszył liczby problemów znaczeniowych przy wykorzystaniu serwisów takich jak Google Translate. Do tej pory istnieje ryzyko napotkania na kuriozalne błędy przy tłumaczeniu nawet najprostszych zdań typu „This coference is gonna make me miss my train”, gdzie zamiast logicznego „Przez tę konferencję przegapię pociąg” uzyskamy „Ta konferencja zmusi mnie do tęsknoty za moim pociągiem”. Angielski czasownik miss posiada wiele znaczeń, a komputer „nie zrozumiał” kontekstu.
Podobne niedociągnięcia są przeszkodą dla programistów, przez którą tłumaczenie maszynowe nie jest w stanie osiągnąć poziomu „ludzkiego parytetu” i stać się rywalem dla ludzi. Jednak w najbliższym czasie sytuacja może się radykalnie odmienić, dzięki wprowadzeniu do tłumaczenia maszynowego technologii Sztucznej Inteligencji (SI). Pierwszym udanym zastosowaniem SI w zakresie analizy językowej była technologia Switchboard służąca do rozpoznawania mowy, którą wykorzystuje asystent głosowy Cortana od Microsoftu. W sierpniu 2017 roku programiści poinformowali, że osiągnęli pięcioprocentowy próg błędów przy transkrypcji mowy żywych ludzi, co zostało nowym rekordem dla/wśród algorytmów mowy.
O osiągnięciu przez tłumaczenie maszynowe ludzkiego poziomu stało się głośno zeszłej jesieni, podczas konferencji WMT 17. Specjaliści Microsoftu z Azji i USA przedstawili pracę nowego programu na testach nowości newtest2017. Specjaliści najęli dwujęzycznych rzeczoznawców, żeby porównać efekty pracy programu i dwóch profesjonalnych tłumaczy. Podczas testowania rzeczoznawcy porównali ponad dwa tysiące zdań przetłumaczonych z języka chińskiego na angielski, pochodzących z różnych serwisów informacyjnych. Oceny otrzymanych od komputerów przekładów pokazały, że technologia Microsoftu po raz pierwszy w historii osiągnęła rezultaty nie odbiegające od ludzkich.
Zainteresowanie specjalistów Microsoftu parą językową angielski-chiński wyjaśnimy wyczerpująco: liczba ludności posługujących się w 2017 roku tymi językami osiągnęło rekordową liczbę 1,2 miliardów ludzi (dla porównania liczebność ludności hiszpańskojęzycznej wynosi 512 milionów, a anglojęzycznej – 1,1 miliarda). Złożoność języka i zróżnicowanie technik tłumaczeniowych były decydującym czynnikiem dla jej testowania w formacie tłumaczenia maszynowego.
Rezultaty wspólnej pracy grupy Microsoft z Pekinu, Redmond i Waszyngtonu zostały wysoko ocenione przez Xuedonga Huanga, technicznego specjalisty Microsoftu w zakresie mowy, języka naturalnego i tłumaczenia maszynowego.
„Osiągnięcie ludzkiego poziomu w tłumaczeniu maszynowym jest marzeniem nas wszystkich – stwierdził programista. My po prostu nie przypuszczaliśmy, że stanie się to tak prędko. Pokonanie barier językowych, by ludzie mogli więcej ze sobą obcować to fantastyka. I jest to sprawa bardzo, bardzo słuszna.
Jednakże przeprowadzone testy nie rozwiązują problemów takich jak zastosowanie tej technologii w systemie czasu rzeczywistego.
Arul Menezes, współkierownik prac naukowo-badawczych grupy Microsoft w zakresie tłumaczenia maszynowego, ukazał szerokie perspektywy wykorzystania tej technologii. Według Menzesa, naukowcy w najbliższym czasie zaadaptują system do tłumaczenia innych par językowych i tekstów z bardziej skomplikowaną gramatyką i leksyką.
Sztuczna inteligencja – krok do wzajemnego zrozumienia się
Technologiczny przełom Microsoftu był możliwy tylko dzięki rozwojowi Sztucznej Inteligencji i jej uczenia przy pomocy głębokich sieci neuronowych. Komputer jest teraz w stanie samodzielnie szukać nowych, kluczowych cech dla klasyfikacji obiektów od prostych do tych złożonych. W odróżnieniu od klasycznego przekładu, opartego na równoległej analizie dwujęzycznych tekstów, SI pozwoliła uzyskać bardziej płynne i naturalne tłumaczenia z wykorzystaniem szerokiego kontekstu słów i zdań.
„Zainspirowało nas to, co robią zwykli ludzie, tacy jak wy i my” – stwierdził Tie-Yan Liu, główny kierownik oddziału badawczego Microsoft w Azji.
Innowacyjne podejście zespołu Microsoft zawiera się w kombinacji kilku metod głębokiego uczenia, w których komputer imituje pracę ludzkiego mózgu. Jedną z takich metod została technika dual learning, gdzie komputer dostrzega własne błędy w tłumaczeniu tekstów z chińskiego na angielski. Do tego wykorzystywane jest równoległe tłumaczenie ekspertów z angielskiego na chiński w rodzaju wzoru.
Badacze stosowali także metodę deliberation networks, której sedno sprowadza się do wielokrotnego tłumaczenia tego samego zdania, w celu uzyskania najlepszego rezultatu. Jak podkreślają programiści, takie podejście pozwala udoskonalać i poprawiać odpowiedzi komputera, adaptując je do tłumaczenia bardziej złożonych tekstów.
Dla zwiększenia dokładności tłumaczeń maszynowych opracowane zostały dwie nowe technologie: joint training i agreement regularization. Joint training oznacza otrzymywanie kolejnych par zdań w tłumaczeniu tych samych tekstów z angielskiego na chiński i odwrotnie, czego rezultatem jest dokładniejszy przekład. Przy wykorzystaniu agreement regularization fragmenty tekstu są sczytywane przez system z lewej do prawej i na odwrót, aby zwiększyć wiarygodność interpretacji tekstów.
Programiści Microsoft uważają, że ich nowe metody pomogą nie tylko innym badaczom tłumaczenia maszynowego,, ale i staną się bazą dla dalszych przełomowych odkryć przy wykorzystaniu Sztucznej Inteligencji.
Dla ludzkiej kreatywności nie ma zastępstwa
 Chociaż nowa technologia Microsoft osiągnęła wcześniej nie dosięgniętą jakość tłumaczenia maszynowego, system jeszcze nie może równać się ludźmi w stylistycznej adaptacji tłumaczonych tekstów. W dowolnym przekładzie znajduje się mnóstwo niuansów, których komputer na razie nie jest w stanie dostrzec i zaadaptować. Nawet dwóch tłumaczy może przedstawić kilka, skrajnie różnych, ale wiernych tłumaczeń tego samego fragmentu tekstu. W przekładzie nie istnieją surowo określone definicje, jak w naukach ścisłych. Ludzie mogą wyrazić jedną myśl przy pomocy wielu słów i wyrażeń, korzystając z myślenia wizualnego. I to właśnie myślenie wizualne jest główną cechą ludzi, niedostępną dla nawet najbardziej zaawansowanych komputerów.
Chociaż nowa technologia Microsoft osiągnęła wcześniej nie dosięgniętą jakość tłumaczenia maszynowego, system jeszcze nie może równać się ludźmi w stylistycznej adaptacji tłumaczonych tekstów. W dowolnym przekładzie znajduje się mnóstwo niuansów, których komputer na razie nie jest w stanie dostrzec i zaadaptować. Nawet dwóch tłumaczy może przedstawić kilka, skrajnie różnych, ale wiernych tłumaczeń tego samego fragmentu tekstu. W przekładzie nie istnieją surowo określone definicje, jak w naukach ścisłych. Ludzie mogą wyrazić jedną myśl przy pomocy wielu słów i wyrażeń, korzystając z myślenia wizualnego. I to właśnie myślenie wizualne jest główną cechą ludzi, niedostępną dla nawet najbardziej zaawansowanych komputerów.
„Tłumaczenie maszynowe jest o wiele trudniejsze od zwykłego rozpoznawania obrazów – stwierdził Ming Zhou, zastępca dyrektora oddziału badawczego Microsoft w Azji. – Ludzie wykorzystują różne słowa do wyrażenia jednego pojęcia i nie sposób jest wskazać, które ze słów jest tym właściwym”.
Brak myślenia twórczego i abstrakcyjnego to główne słabości super inteligentnych komputerów przyszłości i największy przywilej człowieka w świecie zautomatyzowanej produkcji, uważa Viktor Mayer-Schönberger, profesor Uniwersytetu Oksfordzkiego:
„Nawet jeśli komputery staną się mądrzejsze od nas, nie uda im się przewyższyć człowieka w kreatywności. Zdolność do tworzenia – jedna z decydujących cech ludzkich, na równi z myśleniem abstrakcyjnym, albo złożonymi emocjami” – przekonuje Mayer-Schönberger.
Specjaliści od rozwiązań technicznych także odnoszą się sceptycznie do potencjalnego zastąpienia profesjonalnych tłumaczy. Iwan Smolnikow, dyrektor generalny ABBYY Language Services, w swoim felietonie dla E-gazety „Slon” podkreślił, że tłumaczenie maszynowe może być tylko techniczną pomocą, narzędziem dopełniającym dla przyspieszenia pracy specjalisty.
„Tłumaczenie maszynowe przez najbliższe dziesięciolecia, a może nawet nigdy, nie zastąpi profesjonalnych tłumaczy, ale kilkakrotnie zwiększy wydajność ich pracy. Dla przykładu, profesjonalny tłumacz języka angielskiego w ciągu dnia tłumaczy 2,5 tysiąca słów. Ale dając mu do dyspozycji dobrze skonfigurowane tłumaczenie maszynowe i wygodne oprogramowanie, z którym praca i redagowanie jest lekkie, tempo pracy człowieka może wzrosnąć do 4,5-7 tysięcy słów dziennie, co wcześniej wydawało się rzeczą nie do pomyślenia”, – Smolnikow o korzyściach przekładu „hybrydowego”
Historia rozwoju sinologii (dziedzina nauki o Chinach i języku chińskim) potwierdza: język jest żywy, a jego nauka jest niemożliwa bez ludzkiego obcowania. Język chiński – jeden z najjaśniejszych przykładów. Zawiera on w sobie tysiącletnią historię kraju i jego mieszkańców, ich filozofię i kulturę, które mogą interpretować wyłącznie ludzie.
